Mixture of Experts
Aussi appelé : Mixture of Experts · MoE · architecture d'experts · MoEs · mixtures of experts
Mis à jour le
En bref
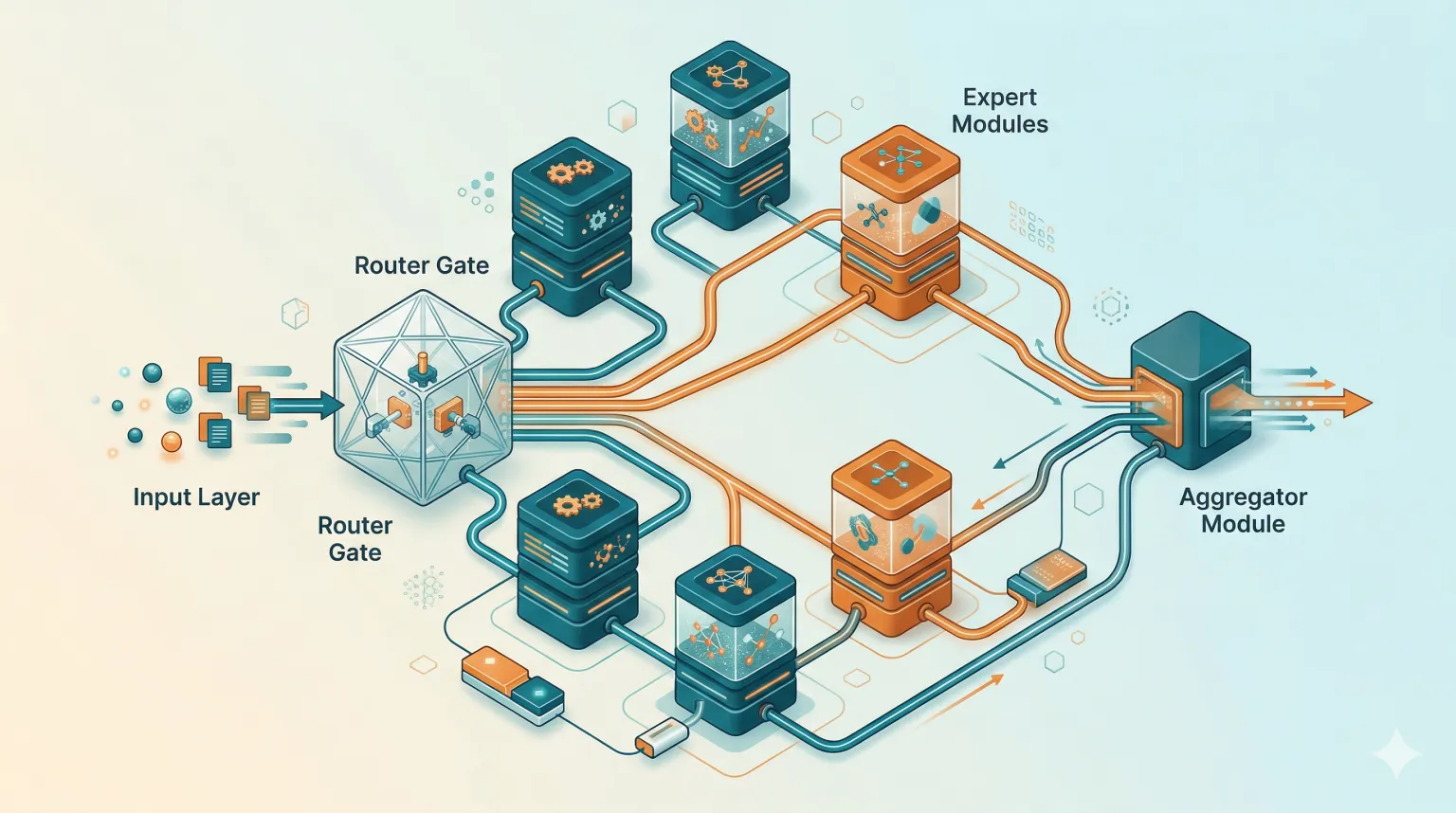
L'architecture Mixture of Experts (MoE) divise un grand modèle en plusieurs sous-réseaux spécialisés, activant seulement les experts les plus pertinents pour répondre à chaque question spécifique.
📖 Définition
💬 En termes simples
Imaginez un grand cabinet multidisciplinaire au centre-ville de Québec : quand un client arrive avec un dossier fiscal, la réceptionniste le dirige vers les deux ou trois spécialistes les plus pertinents plutôt que de mobiliser l'ensemble des 50 professionnels du cabinet. Le cabinet possède une expertise totale immense, mais chaque mandat ne sollicite qu'une fraction ciblée des ressources.
🎯 Exemple concret
En 2026, un fournisseur infonuagique canadien propose un modèle MoE bilingue français-anglais qui active des experts linguistiques distincts selon la langue détectée, offrant une qualité supérieure en français québécois. Une entreprise de jeux vidéo de Montréal utilise un MoE pour générer simultanément des dialogues, des textures et de la musique en activant des experts créatifs différents selon la tâche. Un centre hospitalier universitaire déploie un MoE médical dont certains experts sont spécialisés en radiologie et d'autres en pathologie.
💡 Le saviez-vous ?
Le modèle Mixtral de Mistral AI possède environ 47 milliards de paramètres au total mais n'en active qu'environ 13 milliards par requête, ce qui lui permet de rivaliser avec des modèles beaucoup plus coûteux en calcul. Le concept de Mixture of Experts a été proposé dès 1991 par Robert Jacobs et Geoffrey Hinton, mais il a fallu attendre les avancées matérielles des années 2020 pour qu'il devienne véritablement pratique à grande échelle.
❓ Questions fréquentes
Pourquoi utiliser plusieurs petits experts plutôt qu'un seul grand génie ?
Comment cette approche améliore-t-elle la pertinence des réponses ?
Quels sont les défis techniques liés au MoE ?
📚 Sources
- Mistral AI - Mixture of Experts (Mistral AI, 2023)
- ArXiv - Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer (Shazeer et al., 2017)
🔗 Termes liés
🏷️ Catégorie parente